 |
BMe Kutatói pályázat |

|

BME, Informatikai Tudományok Doktori Iskola
BME VIK, Távközlési és Médiainformatikai Tanszék
Témavezető: Dr. Németh Géza
Statisztikai parametrikus beszédszintézis kiegészítése irreguláris zönge modellel
A kutatási téma néhány soros bemutatása
A statisztikai parametrikus beszédszintézis kutatása hozzájárul az ember-gép kapcsolat jobbá tételéhez, ami az információs társadalom kialakulása során fontos szerepet játszik. A legtöbb beszédtechnológiai módszert ideális beszédre dolgozták ki, és az ettől eltérő esetekkel (például a hangszalagok irreguláris rezgése) kevés kutatás foglalkozott eddig beszédszintézisben. Az irreguláris zöngeképzés (érzetileg rekedtes, érdes beszéd) természetes beszédben is előfordul, és egyes beszélők gyakran használják érzelmek kifejezésére, mondathatár jelzésére vagy hangulat érzékeltetésére az élő beszéd során. Ennek gépi modellezése hozzájárul a természetesebb ember-gép kapcsolat kialakításához.
A kutatóhely rövid bemutatása
A Távközlési és Médiainformatikai Tanszék jogelődjén 1969-ben indult el a beszédkommunikációs területen a kutatás és fejlesztés. A Beszédkommunikáció és Intelligens Interakciók Laboratórium, melyet jelenleg Dr. Németh Géza vezet, kiemelkedő eredményekkel és több évtizedes tapasztalattal rendelkezik a beszédkutatásban, a beszédtechnológia ipari alkalmazásában. A magyar nyelvű gépi beszédszintézis területén számos publikáció valamint alkalmazás köthető a kutatócsoporthoz.
A kutatás történetének, tágabb kontextusának bemutatása
Az információs társadalom kialakulása során fontos az ember-gép kapcsolat folyamatos kutatása, ugyanis széles rétegek számára kell elérhetővé tenni a gépi rendszerek által kínált lehetőségeket. Ennek jó példája az Apple Siri megjelenése. A gépi beszédszintézis célja, hogy írott szöveget alakítsunk át beszéddé, amely lehetőség szerint minél inkább emlékeztet az emberi hangra. A mai rendszerek közül előtérbe kerültek a statisztikai parametrikus módszerek, amelyek gépi tanulást alkalmaznak a beszéd tulajdonságainak reprezentálására [1]. Leggyakrabban a rejtett Markov-modelleket (HMM) használják erre a célra, melyeknek segítségével az eredeti beszélőre emlékeztető, közel természetes gépi beszédhang hozható létre [2].
A modelleket elsősorban reguláris beszédre dolgozták ki, amely során az a feltételezés, hogy a zöngés szakaszokon a hangszalagok rezgése kvázi-periodikus [3]. Ez nagyrészt teljesül is, azonban hosszabb-rövidebb időszakokra a rezgés irregulárissá válhat, azaz ingadozások jelenhetnek meg a periódusonkénti amplitúdóban és / vagy az alapfrekvenciában (F0) [4]. A reguláris és irreguláris beszéd különbségeit az 1. ábra mutatja: a „cipő” szó reguláris változatában az „ő” hang egyenletes periódusokból áll, míg az irreguláris változatban a nyíllal jelölt szakaszon erős amplitúdó ingadozás vehető észre. Ez érzetileg érdes, rekedtes hangot jelent, és a zöngés beszéd akár 15%-ában is előfordulhat, így egyáltalán nem elhanyagolható jelenség [5]. Az irreguláris zönge modellezése a beszédszintézisben hozzájárulhat a személyre szabott, expresszív és természetesebb rendszerek elkészítéséhez.
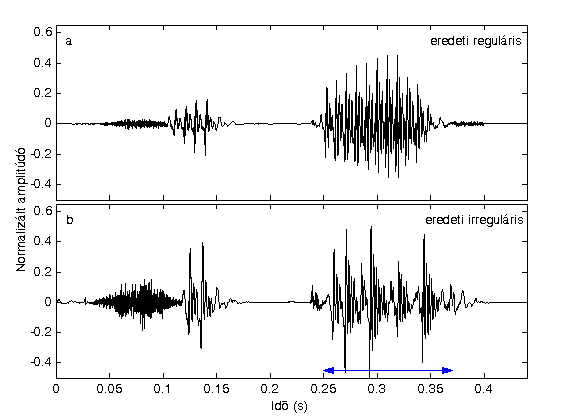
1. ábra: Reguláris és irreguláris zöngével képzett beszéd: a „cipő” szó két változatának hullámformája. Vízszintes nyíl jelöli az irreguláris zöngét.
A kutatás célja, a megválaszolandó kérdések
A szakirodalomban léteznek már módszerek az irreguláris zönge detekciójára [5], [6], reguláris-irreguláris beszéd transzformációjára [3], [7], [8], statisztikai parametrikus beszédszintézisben azonban csak kezdeti kísérletek történtek eddig [9], [10], [11].
A rejtett Markov-modell alapú beszédszintézisben Silén és társai módszerének lényege, hogy robusztus F0 mérést alkalmaz megbízható zöngésség detekcióval, ezáltal eltüntetve az irreguláris beszédrészleteket a szintetizált beszédből [9]. Így viszont a beszélőre jellemző irreguláris fonáció teljesen elveszik a beszédszintézis kimenetéből, és az eljárás nem foglalkozik a megfelelő hangszín visszaállításával. Drugman és társai a DSM modell [12] továbbfejlesztésével analízis-szintézis kísérletekben bemutatják, hogy a másodlagos impulzusok jelenléte megfelelően modellezi az irreguláris beszédet [10]. Raitio és kollégái ezután a rejtett Markov-modell alapú beszédszintetizátorba integrálják a kiegészített modellt [11]. A legújabb kutatás eredményei szerint azonban az új rendszer mintáit csak kis arányban érezték jobbnak az eredeti mintáknál a kísérleti alanyok.
Az irreguláris zöngeképzés természetes beszédben is előfordul, és egyes beszélők gyakran használják érzelmek kifejezésére, mondathatár jelzésére vagy hangulat érzékeltetésére az élő beszéd során [5], [12]. Kutatásunk során azt vizsgáljuk, hogy a statisztikai parametrikus beszédszintézis kiegészítése irreguláris zönge modellel milyen mértékben járul hozzá a természetesebb ember-gép kapcsolat kialakításához. Ehhez két új módszert hoztunk létre az irreguláris beszéd modellezésére, majd az eredményeket szubjektív meghallgatásos tesztekben és akusztikus elemzés során vizsgáltuk.
Módszerek
A kutatás során a beszédtechnológiában ismert és alkalmazott módszereket egészítettük ki új eljárásokkal. A statisztikai parametrikus beszédszintézis során nem közvetlenül a beszédadatbázis hullámformáin végzünk átalakításokat, hanem a beszédet először paraméterekre bontjuk, amelyeket gépi tanuló algoritmus kezel a továbbiakban. A gépi tanítás után a szintézis lépésben állítjuk elő a beszédet.
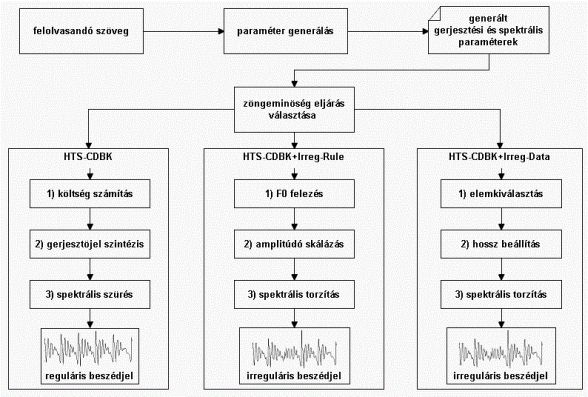
2. ábra: A reguláris zönge modell és a két új irreguláris zönge modell sematikus működése beszédszintézis során.
Új típusú beszéd reprezentációja statisztikai parametrikus beszédszintézisben
A paraméterekre bontásra egy új algoritmust készítettem [C1], amely az analízis lépés során a beszéd gerjesztő jelét felhasználva zönge-szinkron periódusokból álló kódkönyvet épít. Emellett a beszédet a hullámforma tárolása helyett gerjesztési és spektrális paraméter folyamokkal reprezentálja. A paraméterek tudatos módosításával változtatni lehet az eredeti beszéd intonációját, zöngeminőségét, így az érzeti érdességét is. A változtatott paraméterekből végül rekonstruálni tudjuk az eredeti beszéd hullámformát [C1].
A fenti analízis-szintézis eljárást a rejtett Markov-modell alapú beszédszintetizátorba illesztettem [J1], amelyet a későbbiek során alaprendszernek használtam (2. ábra bal oldal, HTS-CDBK). Ezzel a beszédszintetizátorral tehát tetszőleges magyar nyelvű szöveget emberi hangú beszéddé lehet alakítani, az irreguláris zönge előfordulása azonban még nem modellezett. A 3. a) ábra egy példát mutat egy szintetizált szóra az alaprendszerrel.
Szabály alapú irreguláris zönge modell
Az irreguláris beszéddel képzett beszéd vizsgálata során több olyan különbséget észrevettem a reguláris zöngéhez képest, amelyeket szabályokkal megfelelően lehet modellezni [C2, J2]. A 2. ábra középső része mutatja a létrehozott modell lépéseit (HTS-CDBK+Irreg-Rule). 1) Az irreguláris zönge esetén a hangszalagok rezgése eltér a kvázi-periodikustól, és a beszéd alapfrekvenciája (F0) akár extrém alacsony is lehet a normál beszédhez képest. Ezt kihasználva a szintézis során a paraméterekre bontott beszéd F0 értékei helyett azoknak felét használom. 2) Az irreguláris zönge képzésekor erős amplitúdó-ingadozás jelenik meg az egymás utáni periódusokban (ld. 1. ábra). Ennek modellezésére periódusonkénti amplitúdó-skálázást alkalmazok: az egymás utáni zöngeperiódusok értékét {0...1} közötti véletlen számokkal szorzom meg. 3) Az irreguláris zöngéjű beszéd hangszíne kis mértékben eltér a reguláris hangtól. Ahhoz, hogy ezt modellezzük, egy spektrális torzító lépést vezettem be. A szabály alapú irreguláris zönge modell eredményét a 3. b) ábra mutatja.
Adatvezérelt irreguláris zönge modell
Az irreguláris zönge modellezése adatvezérelt módon is megtörténhet [J2]. A 2. ábra jobb oldalán látható ennek módszere (HTS-CDBK+Irreg-Data). Az új modellben a korábban felvett beszédadatbázisból választunk ki irreguláris zöngével képzett szakaszokat, amelyeket szintézis során használunk fel. 1) Az elemkiválasztás művelet [13] biztosítja, hogy az adott mondathoz megfelelő irreguláris gerjesztőjelet találjuk meg. 2) A kiválasztott szakasz hosszát a cél magánhangzónak megfelelő hosszúságra állítjuk, 3) majd a szabály alapú modellhez hasonlóan spektrális torzítást alkalmazunk. A 3. c) ábra egy példát mutat az adatvezérelt irreguláris modell szintetizált szavára.
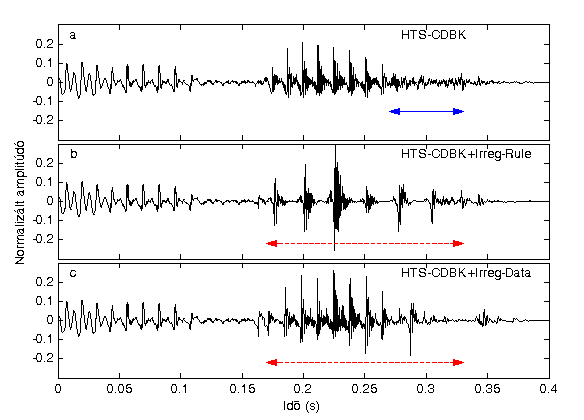
3. ábra: A „Mihály” szó szintetizált beszéd hullámformái a) alaprendszer b) szabály alapú irreguláris zönge modell c) adatvezérelt irreguláris zönge modell.
Eddigi eredmények
Az alaprendszer és a két irreguláris zönge modell közti különbség jól látható a 3. ábrán. Az a) ábra vízszintes vonallal jelölt részén az alaprendszer zöngéje nem megfelelő, gerjesztésváltás látható az „á” hangon belül, ami meghallgatva csattanó hangként zavarja a szintetizált beszéd érthetőségét. A b) ábrán nyíllal jelölt szakaszon jól látszik az F0 csökkentés eredménye a szabály alapú modellben: az egyes periódusok elkülönülnek, ami által a beszédhang több akusztikus, hallható szempont szerint is emlékeztet a rekedtes beszédre. Emellett az amplitúdó ingadozás hasonlít az 1. ábra eredeti irreguláris mintájára. A c) ábrán az adatvezérelt irreguláris zönge kimeneteként csak az „á” hang második fele mutat irreguláris jelleget, mivel természetes beszédben is sokszor csak a beszéd kisebb része rekedtes.
Adatbázisok és hangminták
A modellek teszteléséhez a PPBA beszédadatbázis [14] két férfi beszélőjét választottam ki. Mindketten gyakran használtak irreguláris zöngeképzést, elsősorban szakaszhatárokon. A beszélőktől 1940 mondatot (kb. 2 órányi felvétel) használva HMM alapú beszédhangot készítettem mindhárom módszerrel (alaprendszer, szabály alapú valamint irreguláris zönge modell). Ezután 130 mondatot szintetizáltam szövegből beszéddé, melyekből 10-10 mintát választottam ki a későbbi elemzésekhez. A mintákban a mondatok egy-egy irreguláris zöngével képzett szava szerepelt. Néhány ilyen példa szó meghallgatható az 1. táblázat hivatkozásaira kattintva.
1. táblázat: Szintetizált beszéd minták a PPBA adatbázis két beszélőjétől. Teljes lejátszható változat.
HTS-CDBK (reguláris zönge) |
HTS-CDBK+Irreg-Rule (szabály alapú irreguláris) |
HTS-CDBK+Irreg-Data (adatvezérelt irreguláris) |
Meghallgatásos tesztek
A szintetizált beszédminták értékelését szélesebb körben is elvégeztem: internetes meghallgatásos teszteket készítettem [C2], [J2]. Az 1. tesztben a szabály alapú irreguláris zönge modellt hasonlítottam össze az alaprendszerrel, míg a 2. tesztben az adatvezérelt irreguláris modellt értékeltettem. Minden hangminta pár meghallgatása után két kérdésre kellett válaszolniuk a kísérleti alanyoknak kellemesség és az eredeti beszélőre való hasonlóság szempontjából.
Az 1. tesztet 11 tesztelő (beszédtechnológiai szakértők) töltötte ki átlagosan 9 perc alatt, míg a 2. tesztben összesen 16 kísérleti alany (egyetemi hallgatók) vett részt. A kérdésekre adott válaszokat párosított mintás t-teszttel és ANOVA analízissel vizsgáltam. Az 1. percepciós teszt eredménye szerint a tesztelők az új, HTS-CDBK+Irreg-Rule mintákat szignifikánsan (p<0.0005) természetesebbnek érezték, mint a HTS-CDBK alaprendszert. Emellett az új modell mintái szignifikánsan (p<0.0005) jobban emlékeztetnek az eredeti beszélőre. A 2. teszt hasonló preferenciát mutatott a HTS-CDBK+Irreg-Data rendszer irányába az alaprendszerrel szemben.
A szubjektív meghallgatásos tesztek konklúziója, hogy a tesztben résztvevő kísérleti alanyok egyértelműen elfogadták az új modellekkel szintetizált beszédmintákat, vagyis a módszerek felhasználhatóak gépi rendszerekben.
Akusztikus elemzés
A szintetizált beszédmintákat akusztikus elemzés során is összehasonlítottam, melynek részletei [C2] és [J2] cikkekben olvashatóak. Az akusztikus vizsgálatok eredménye szerint az irreguláris zönge modellekkel szintetizált beszédminták több releváns akusztikai jegy szempontjából is közel vannak az eredeti, természetes irreguláris beszédmintákhoz.
Várható impakt, további kutatás
Az irreguláris zöngeképzést gyakran használjuk érzelmek kifejezésére vagy mondathatár jelzésére az élő beszédben [5], [12]. A kutatásunk során kidolgozott két alternatív irreguláris zönge modell tovább javítja a beszédszintézis természetességét. Ilyen rendszer segítségével lehetőség van személyre szabott, vagyis az adott beszélő hangján megszólaló gépi rendszer kialakítására. Ez mobiltelefonos alkalmazásokban hasznos lehet beszédsérültek kommunikációjának segítésére. Emellett a modellek segíthetik az expresszív, érzelmekkel kiegészített beszéd gépi előállítását.
A jelen kutatás aktualitását mutatja, hogy több külföldi kutatócsoport (Trinity College Dublin, University of Mons, Aalto University) is foglalkozik hasonló irreguláris zönge vizsgálatokkal. A beszédtechnológia legnagyobb konferenciáin (Interspeech 2012, Interspeech 2013, ICASSP 2013) jó néhány cikk foglalkozott ezekkel a témákkal, pl.: [10], [11], [15].
Saját publikációk, hivatkozások, linkgyűjtemény
Kapcsolódó saját publikációk listája:
[J1] Tamás Gábor Csapó, Géza Németh, Statistical parametric speech synthesis with a novel codebook-based excitation model. Intelligent Decision Technologies, elfogadva, 2013.
[J2] Tamás Gábor Csapó, Géza Németh, Modeling irregular voice in statistical parametric speech synthesis with residual codebook based excitation. IEEE Journal on Selected Topics in Signal Processing, elfogadva, 2013.
[C1] Tamás Gábor Csapó, Géza Németh, A novel codebook-based excitation model for use in speech synthesis. in IEEE CogInfoCom 2012, (Kassa, Szlovákia), 661–665. old., 2012.
[C2] Tamás Gábor Csapó, Géza Németh, A novel irregular voice model for HMM-based speech synthesis. in Proc. ISCA 8th Speech Synthesis Worksop (SSW8), 229-234. old., 2013.
Linkgyűjtemény:
Statisztikai parametrikus beszédszintézis
HMM-alapú beszédszintézis rendszer (HTS) nyílt forráskódú változata
1000 beszédhang HMM-alapú beszédszintézisben
Zöngeminőség minták (angol reguláris, angol irreguláris, angol levegős)
A pályázatban szereplő szintetizált irreguláris zönge beszédminták
Hírességek is használják az irreguláris zöngét
Gépi beszédszintézist használó időjárás előrejelző program Windows 8-ra
Hivatkozások listája:
[1] H. Zen, K. Tokuda, and A. W. Black, Statistical parametric speech synthesis. Speech Communication, vol. 51, 1039–1064 old., Nov. 2009.
[2] B. Tóth and G. Németh, Improvements of Hungarian Hidden Markov Model-based Text-to-Speech Synthesis. Acta Cybernetica, vol. 19, no. 4, 715–731. old., 2010.
[3] D. H. Klatt and L. C. Klatt, Analysis, synthesis, and perception of voice quality variations among female and male talkers. The Journal of the Acoustical Society of America, vol. 87, 820–857. old., Feb. 1990.
[4] M. Blomgren, Y. Chen, M. L. Ng, and H. R. Gilbert, Acoustic, aerodynamic, physiologic, and perceptual properties of modal and vocal fry registers, The Journal of the Acoustical Society of America, vol. 103, 2649–2658. old., May 1998.
[5] T. Bőhm, Z. Both, and G. Németh, Automatic Classification of Regular vs. Irregular Phonation Types, in NOLISP, (Vic, Spain), 43–50. old., 2009.
[6] J. Kane, T. Drugman, and C. Gobl, Improved automatic detection of creak, Computer Speech & Language, vol. 27, 1028–1047. old., June 2013.
[7] A. McCree and T. Barnwell, A mixed excitation LPC vocoder model for low bit rate speech coding, IEEE Transactions on Speech and Audio Processing, vol. 3, 242–250. old., July 1995.
[8] T. Bőhm, N. Audibert, S. Shattuck-Hufnagel, G. Németh, and V. Aubergé, Transforming modal voice into irregular voice by amplitude scaling of individual glottal cycles, in Acoustics’08, (Paris, France), 6141–6146. old., 2008.
[9] H. Silén, E. Helander, J. Nurminen, and M. Gabbouj, Parameterization of vocal fry in HMM-based speech synthesis, in Proc. Interspeech, (Brighton, UK), 1775–1778. old., 2009.
[10] T. Drugman, J. Kane, and C. Gobl, Modeling the Creaky Excitation for Parametric Speech Synthesis, in Proc. Interspeech, (Portland, Oregon, USA), 1424–1427. old., 2012.
[11] T. Raitio, J. Kane, T. Drugman, and C. Gobl, HMM-based synthesis of creaky voice, in Proc. Interspeech, 2316-2320. old. , 2013.
[12] T. Drugman, G. Wilfart, and T. Dutoit, A deterministic plus stochastic model of the residual signal for improved parametric speech synthesis, in Proc. Interspeech, (Brighton, UK), 1779–1782. old., 2009.
[13] A. Hunt and A. Black, Unit selection in a concatenative speech synthesis system using a large speech database, in Proc. ICASSP, vol. 1, (Atlanta, Georgia, USA), 373–376. old., 1996.
[14] G. Olaszy, Precíziós, párhuzamos magyar beszédadatbázis fejlesztése és szolgáltatásai [Development and services of a Hungarian precisely labeled and segmented, parallel speech database] (in Hungarian), Beszédkutatás 2013 [Speech Research 2013], 261-270. old. , 2013.
[15] T. Drugman, J. Kane, T. Raitio, and C. Gobl, Prediction of Creaky Voice from Contextual Factors, in Proc. ICASSP, (Vancouver, Canada), 7967-7971. old., 2013.